About
Authors
Grigori Fursin - CTO, dividiti; Chief-Scientist, cTuning Foundation
Anton Lokhmotov
Information
Type: Workflow Builder, Automation Tool, Metadata Library, Digital Archive
License: 3c-BSD
Timeline: 2014-present
Institution: cTuning Foundation (non-profit)
Links
cTuning website for Collective Knowledge
Demo "Interactive Paper" for CK Browser
Rubric
✔ - Yes
✗ - No
○ - Yes, but with concession
· - Inapplicable
? - Unknown
| Infrastructure | ||
| Self-Hosting | ✔ | |
| Provides Metadata | ✔ | |
| Provides Hardware Diversity | ✗ | |
| Dispatches Work to Cloud Machines | ✗ | |
| Provides a Web Portal | ✔ | |
| Provides Performance Monitoring | ✗ |
| Capabilities | ||
| Runs Code | ✔ | |
| File Storage | ✗ | You host packages externally using something like github. |
| Collaboration Controls | ❓ | |
| Provides Citations | ✔ | |
| Interactive Graphing | ✔ | You can generate reports that embed javascript widgets and there is a graph tool that takes a json description of the graph. |
| Can Combine Objects | ✔ | |
| Can Archive/Run GUI Tools | ✗ | |
| Can Hook to External Services | ✗ |
| Access | ||
| Public view of object | ✔ | Through a webserver, generated pages can be made public. |
| Access Permissions for Editing | ❓ | |
| Access Permissions for Reading | ❓ | |
| Access Permissions for Anon Review | ❓ | |
| Embeddable Access | ✗ |
| Provenance | ||
| Search | ✔ | |
| Unique Identifiers for Projects | ✔ | A type of UUID and use of URIs. |
| Provides URL to Project / Data | ✔ |
| Governance | ||
| Open Source | ✔ | |
| Allows Modification / Redistribution | ✔ | |
| Has a Free-to-Use Package | ✔ | |
| Has a Student Package | · | |
| Has a Paid Package | · |
Motivation
From their own page at http://cknowledge.ddns.net/:
We have developed Collective Knowledge framework and repository (CK) to help researchers quickly prototype their research ideas, crowdsource experiments and reproduce results using shared CK modules with unified JSON API, while simplifying predictive analytics and knowledge exchange. For example, CK already helped computer systems' researchers (and ourselves):
- share realistic programs, benchmarks, and data sets (shared CK repos);
- automate and crowdsource performance analysis, benchmarking and tuning (online crowd results);
- perform automatic multi-objective compile-time and run-time optimizations (e.g. cost vs. performance vs. energy vs. accuracy) achieving 10x speedups and 50% energy reductions with the same accuracy for some real OpenCL/CUDA applications on the latest heterogeneous platforms;
- apply statistical ("machine learning") techniques (e.g. building performance/energy models, quickly identifying performance bottlenecks, accelerating autotuning);
- simplify optimization knowledge sharing across communities of hardware vendors and software developers;
- stress-test compilers and crowd-tune their optimization heuristics on representative workloads;
- enable interactive graphs and papers (demo).
Collective Knowledge warns about the prevailing model of development and research where software is rapidly developed and released but not organized. It becomes hard to understand, discover, and replicate an ever increasing number of software tools. Therefore, Collective Knowledge exists to encapsulate tools in a way to give them some consistency in their use to allow for that replication and automation.
http://ctuning.org/
Walkthrough
In this section, we will walk through the process of describing and running an experiment. We will focus on the methods the framework uses to combine various artifacts (typically datasets) together. There will be thorough markup of any metadata along the way. We will emphasize working with an existing artifact.
First, there is a mechanism to pull down existing repositories from their central GitHub organization to your local machine:
ck pull repo:ctuning-programs
Assuming we have a collection of objects already, we can run an experiment workflow through the command-line.
Most of the framework is to be used via the command-line. The following will run the given program set cbench‑automotive‑susan
which is a pre-prepared object:
ck pipeline program:cbench-automotive-susan --speed
Which will list the programs we can run:
0) corners ($#BIN_FILE#% $#dataset_path#$$#dataset_filename#$ tmp-output.tmp -c)
1) edges ($#BIN_FILE#% $#dataset_path#$$#dataset_filename#$ tmp-output.tmp -e)
2) smoothing ($#BIN_FILE#% $#dataset_path#$$#dataset_filename#$ tmp-output.tmp -s)
Select item (or press Enter for 0): _
In this case, the same program has three different invocations. Each is available to run
through this interactive prompt. They simply switch between three different program commands
which ultimately are just selecting an input flag among ‑c, ‑e, and ‑s.
I'm not sure how to automatically select the program to avoid the interaction.
After you select the program it will query for any datasets that can be used as input: Note the name of the dataset and then the uuid in parens.
0) image-pgm-0001 (b2130844c38e4a56)
1) image-pgm-clean-gray-square-600-450-8 (c5a378cde441bbb7)
2) image-pgm-from-pamela-100 (d11ad4b49f2b9f45)
Or, you can automatically use a dataset by specifying it as a parameter:
ck pipeline program:cbench-automotive-susan --speed --dataset_uoa=image-pgm-0001
After selecting the dataset, it will run the workflow.
Metadata
The "cbench-automotive-susan" experiment is described through metadata. The program is located in
CK_ROOT_/ctuning‑programs/program/cbench‑automotive‑susan and within the .cm path inside there are three JSON metadata files.
The desc.json seems to describe repetitions and exploration parameters.
The info.json describes the artifact's name and description. This is descriptive metadata including permissions metadata and some info about where backups are contained. Apparently backups have their own unique uuid.
The meta.json describes how to run the artifact automatically and what datasets it supports. It tells you how to compile it:
{
...
"compiler_env": "CK_CC",
"source_files": [
"susan.c"
],
"main_language": "c",
"extra_ld_vars": "",
...
}
And it describes the various ways to invoke the program once it is built:
{
...
"run_cmds": {
"corners": {
"dataset_tags": [
"dataset", "image", "pgm"
],
"hot_functions": [
],
"run_time": {
... info about how to run and where to put stdout etc ...
"run_cmd_main": "$#BIN_FILE#$ $#dataset_path#$$#dataset_filename#$ tmp-output.tmp -s"
}
},
"edges": {
...
},
"smoothing": {
...
}
}
...
}
Each key became one of the options listed in the section above where we run the experiment.
Dataset Selection
The programs are matched to possible datasets which can be packaged independently of the experiment workflow.
That is, datasets and files can be new included or can be pulled from other experiments for use in otherwise disparate experiments.
This is done by specifying the tags for the dataset, as is done above, in the dataset_tags section.
The framework will search for datasets that share those tags and list them interactively.
One dataset that can be used here is located in CK_ROOT/ctuning‑datasets‑min/dataset/image‑pgm‑0001 and it has
its own metadata in meta.json:
{
"cm_classes_uoa": [
"62a455f8c8042f90",
...
],
"cm_dissemination": {
"publications": [
"0c44d9a2db3de3c9",
...
]
},
"cm_properties": {
"color_depth": "8",
"gray": "yes",
"height": "450",
"image_type": "computer generated landscape",
"type": "image",
"width": "600"
},
"dataset_files": [
"data.pgm"
],
"tags": [
"dataset",
"image",
"pgm"
]
}
As you can see, its tags match those specified in the experiment. The dataset metadata describes several type-dependent properties and a data file data.pgm which is
a form of raw grayscale image data.
You can compile programs separately with:
ck compile program:cbench-automotive-susan --speed
But it seems like it will compile programs to run them within the pipeline if needed.
Infrastructure
Capabilities
Collective Knowledge can run code against arbitrary inputs and datasets. Furthermore, code can be abstracted and have variables that can be set or explored allowing for a machine learning or crowd-sourced approach.
Collective Knowledge Browser has support for generating interactive graphs based on data and styled given by JSON metadata. You can modify this JSON to refactor and redisplay the graph.
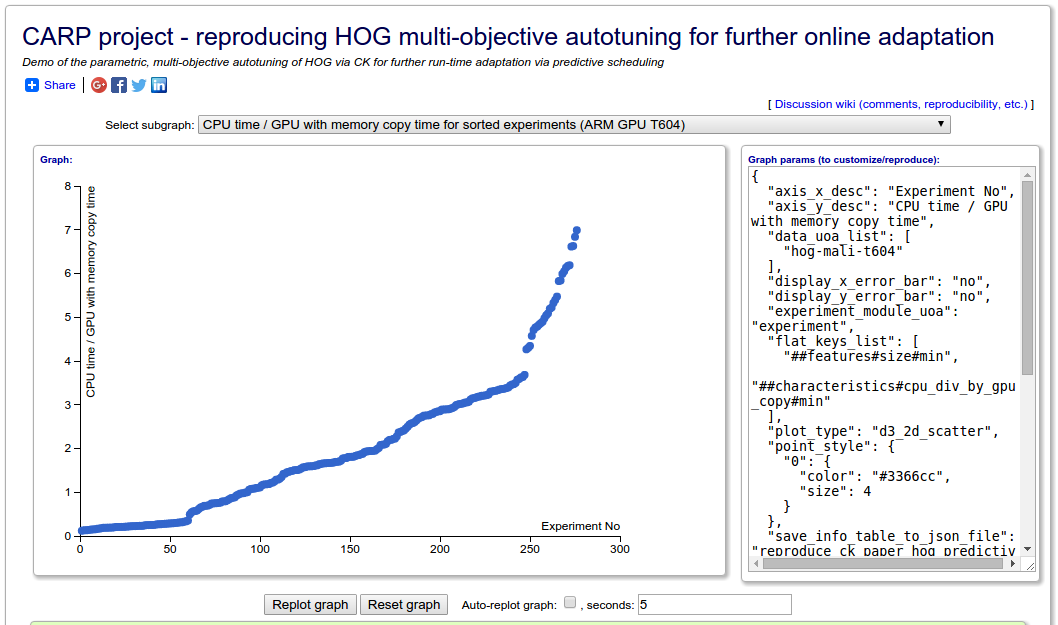
The interactive graphing component of Collective Knowledge Browser allows others to explore data generated by an object.
From the graph, you can see links to the experiment, the data within the graph, and other information to point you toward anything that could be used to replicate and reproduce the results.
Access
To be discussed.
Provenance
Collective Knowledge identifies objects using a globally unique identifier. These can be used to reference other objects within object and they can be used as a key in a search. Objects can also be discovered by a search via tags.
As mentioned, interactive and exploratory components also point back toward the experiment or data that are involved. This allows for greater transparency in the generation of plots such that replication of those results is possible.
Governance
Collective Knowledge is an open source project. It is licensed under a permissive three-clause BSD license. This will allow for modification and redistribution of the source code for any reason. This speaks to availability and longevity of the software and people's ability to make use of it in the future.
Strengths
The main motivation of Collective Knowledge is to abstract details related to the composition of software such as variables that affect how it builds and what inputs it takes. This allows for a greater extensibility of artifacts and experiments that are wrapped in the framework. Compiler automation, which seems to be a general focus of the authors of the framework, is made possible through this abstraction. Programs and benchmarks can be compiled under different conditions and measured against a variety of datasets automatically. This type of automation is furthermore done in a way that promotes replication and then reproduction on other machines. Their own usecase is to crowd-source those parameters by automatically selecting them across a system of machines and weighing them by performance metrics.
Breakdown
- Abstracts Compilation and Input Sources
- Automation of Experiment Workflows
Weaknesses
For as much as Collective Knowledge can do, there is a vagueness about what it cannot do.
Breakdown
- Metadata Complexity
- No Virtualization Features
Unique Features
A generalized method to perform automation with respect to configuring tools or compiling software.
Best-Practice Influences
Collective Knowledge is built around the idea of repeatability and exhibits how good standards behind repeatability can mean a faster and more reliable means of performing research. This framework pushes people to understand what parts of their system are automatable by rewarding that effort with an extensible tool to perhaps, at least with some amount of optimism, crowdsource the best parameters to promote the best or most interesting result.
Digital Library Incorporation Issues
To capture a Collective Knowledge artifact, it is generally a git repository containing code and metadata. A library of Collective Knowledge artifacts will store these repositories at a git server. Collective Knowledge artifacts can reference other artifacts either directly or indirectly. To best serve the needs of experimentation and reproducibility, all direct relationships must be stored together with the same longevity guarantees and there should be some reasonable availability of a representative subset of indirectly related artifacts (datasets, etc) which are stored in the same fashion (git repo including metadata)