About
Authors
Gary King - Principal Investigator
Mercè Crosas - Principal Investigator
Gustavo Durand - Development Manager
Leonid Andreev - Developer
Stephen Kraffmiller - Developer
Phil Durbin - Developer
Raman Prasad - Developer
Michael Bar-Sinai - Developer
Elizabeth Quigley - UI/UX
Michael Heppler - UI/UX
Kevin Condon - QA and Support
Sonia Barbosa - Curation and Archival
Eleni Castro - Curation and Archival
Dwayne Liburd - Curation and Archival
Information
Type: Metadata/File Archive
License: Apache 2.0
Timeline: 2012-present
Institution: Harvard University
Funding: Sloan Foundation, NSF, Helmsley Charitable Trust
Links
Main Site (dataverse.org)
Harvard Dataverse (dataverse.harvard.edu)
Source Code - GitHub
Map of Dataverses - Google Maps
Motivation
Taken from their academic credit page:
By depositing data into Dataverse, which can be customized or embedded into a website with our Theme + Widgets feature, researchers make their datasets more discoverable to the scientific community. Widgets are available at the Dataverse and dataset level and can be embedded in any website to help others find a scholar's datasets more easily.
By increasing research data's visibility with Dataverse, researchers can get recognition and proper academic credit for their scholarly work through a Data Citation. These citations also help ensure that research data meet funder and publisher requirements; reused by other scholars; replicated for verification; and tracked to measure usage and impact over time, which can help fund future research.
Rubric
✔ - Yes
✗ - No
○ - Yes, but with concession
· - Inapplicable
? - Unknown
| Infrastructure | ||
| Self-Hosting | ✔ | You can and are encouraged to host your own Dataverse instance. There are guides for installing and also information about how to customize the look and feel. Many already exist. |
| Provides Metadata | ✔ | |
| Provides Hardware Diversity | ✗ | Does not run code, just does file hosting. |
| Dispatches Work to Cloud Machines | ✗ | |
| Provides a Web Portal | ✔ | Exists entirely as a web-based digital library. |
| Provides Performance Monitoring | ✗ |
| Capabilities | ||
| Runs Code | ✗ | |
| File Storage | ✔ | 2GB limit per file. Can add tags and description per file. |
| Collaboration Controls | ✔ | |
| Provides Citations | ✔ | Metadata is centered around citations. Provides EndNote XML and RIS formatted citations. |
| Interactive Graphing | ✗ | |
| Can Combine Objects | ✗ | |
| Can Archive/Run GUI Tools | ✗ | |
| Can Hook to External Services | ✔ | Can upload files and replicate from Dropbox. |
| Access | ||
| Public view of object | ✔ | Artifacts are unpublished to start and then can be made public upon pressing a Publish button. |
| Access Permissions for Editing | ✔ | |
| Access Permissions for Reading | ✔ | |
| Access Permissions for Anon Review | ✗ | No controls to make artifacts anonymous for the sake of review. |
| Provenance | ||
| Search | ✔ | Keyword/Tag based. Has categories for the field of research. |
| Globally Unique Identifiers for Projects | ✔ | Generates DOIs for content. |
| Provides URL to Project / Data | ✔ |
| Governance | ||
| Open Source | ✔ | Apache v2.0 |
| Allows Modification / Redistribution | ✔ | |
| Has a Free-to-Use Package | ✔ | The main site is the Harvard Dataverse which is open to all. |
| Has a Student Package | · | |
| Has a Paid Package | · |
Walkthrough
After creating an account, you can now see the "Add Data" dropdown. Here you can create a dataverse or just add data to an existing dataverse.
A dataverse is a collection of data. Each dataverse can itself contain other dataverses. This creates a type of hierarchy of information.
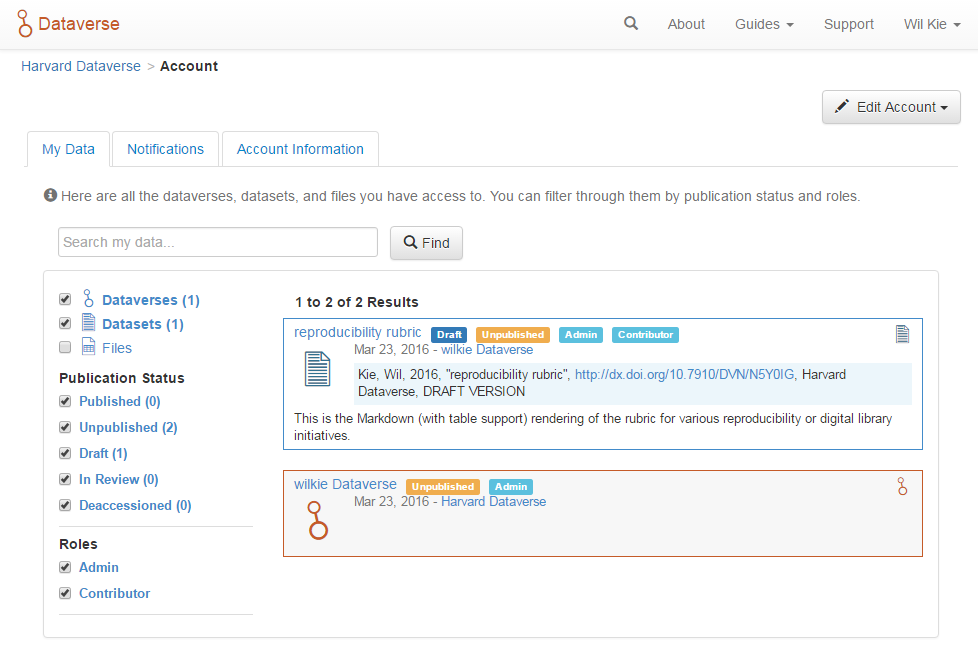
Your dashboard shows the datasets and dataverses that belong to you.
You can create a new dataverse simply by filling out a form. The form represents the metadata for the dataverse. You can specify which fields can be used for search facets for searching artifacts that are listed within that dataverse.
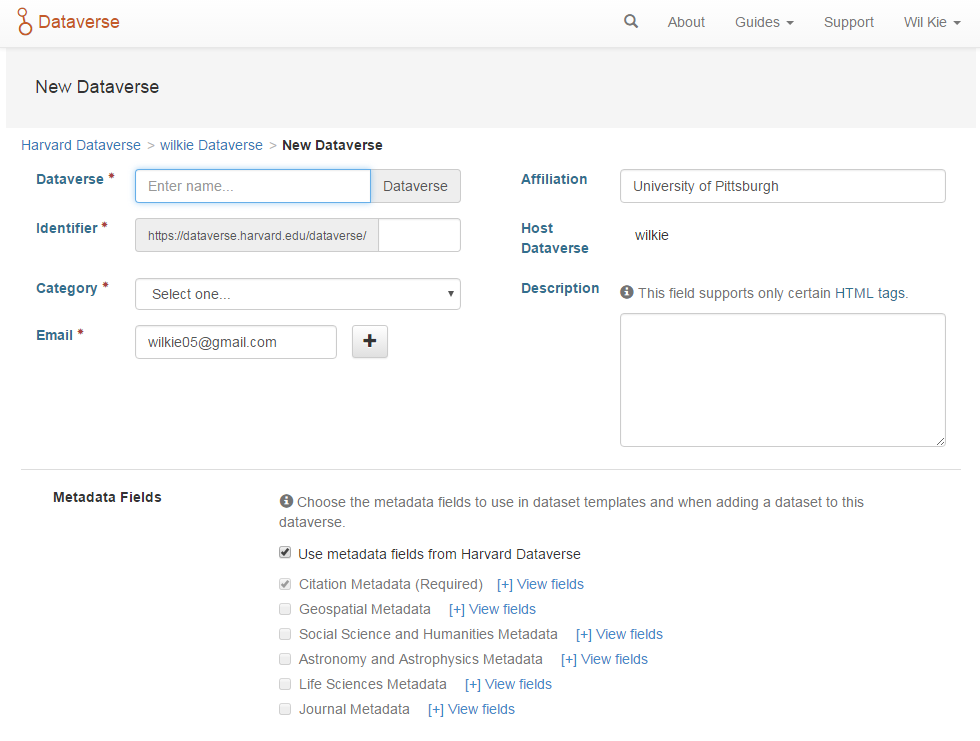
The creation of a dataverse.
Once you have a dataverse, you can add data to that dataverse in a similar fashion. The New Dataset form allows you to specify citation-inspired metadata. You give the authors and contact information along with a simple HTML description.
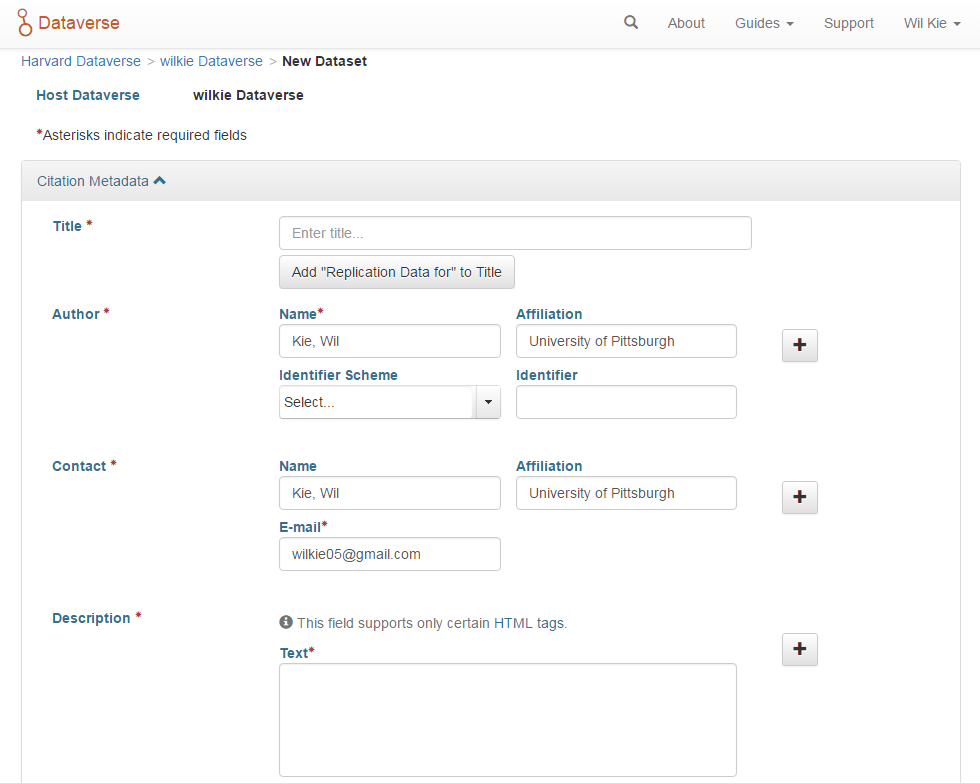
The creation of a dataset with a dataverse.
Once you have a dataset, you can upload files. You can upload any number of files up to 2GB per file. For each file, you can specify a description. The system will also tag the file with a MD5 hash and keep statistics about when the file was uploaded, its size, and the number of times it was downloaded. You can also pull files down from Dropbox, an external "cloud" storage service.
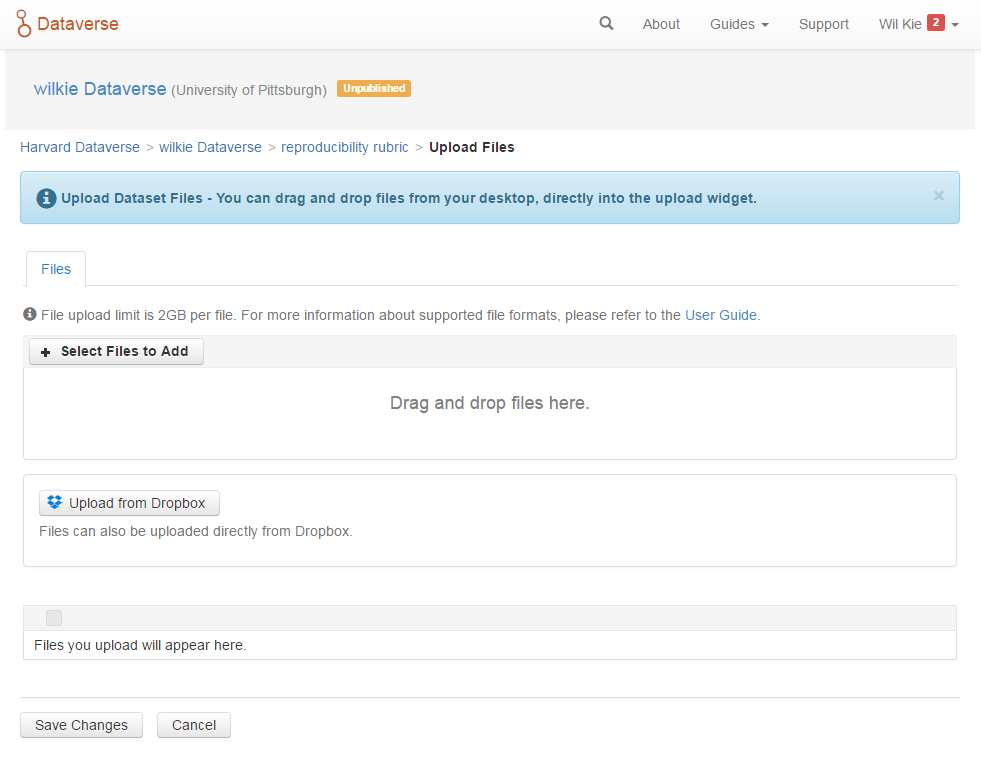
You may upload a set of files to a dataset.
Once you have download a set of files to your dataset, you have an unpublished draft. You can review this draft and also assign other users access to read or edit it. Once you wish to make it discoverable by other users (allow a public view) you can press the "Publish" button.
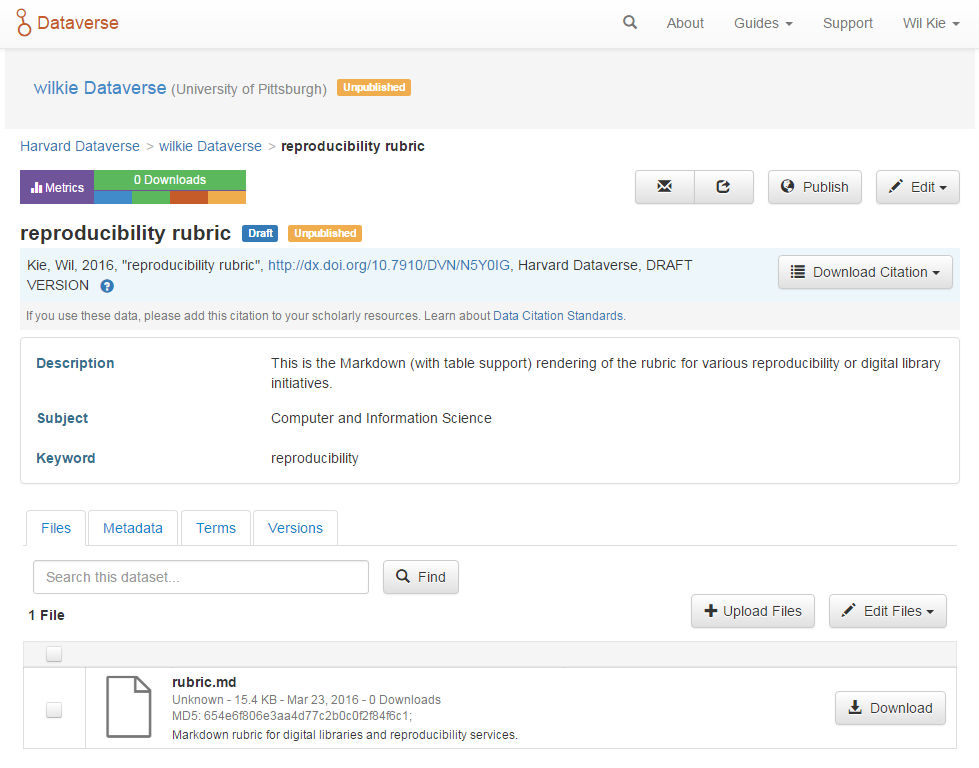
An unpublished artifact within Dataverse.
Once published, an article is discoverable through searching the dataverse or any parent dataverse. The artifacts can be discovered through the facets made available from the dataverse they are contained it and through keyword searches using the metadata provided including any long-form descriptions. Citations can be generated and downloaded in several formats.
Infrastructure
Dataverse servers do not execute code and thus do not provide any isolation or virtualization capabilities. They host files and metadata and store relationships among them. Files can be up to 2GB in size. There is no policy about the availability of the files with respect to the network bandwidth, but there is a policy governing the longevity and robustness of the network at the Harvard instance.
Capabilities
The system allows for the hierarchal storage of datasets. Dataverses are a collection of content typically a categorical grouping of related data. The categories are defined by the collector. Dataverses can contain other dataverses which contain dataverses, etc. Dataverses can contain many datasets which in turn contain many files.
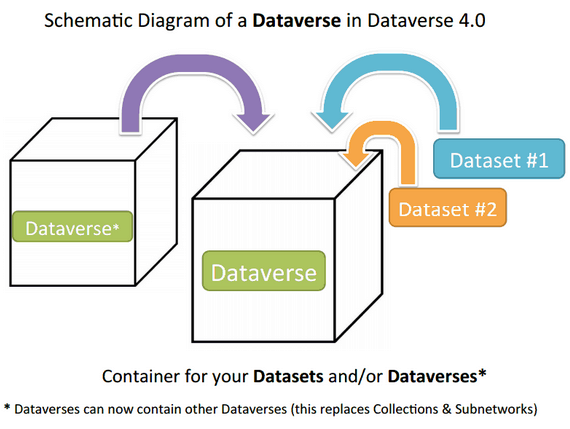
The Dataverse system model.
Metadata can be provided/edited by the uploader or curator. DOIs are generated for each dataset and dataverse. These DOIs are globally unique identifiers.
Access
The Dataverse has a sophisticated role-based access control mechanism. For every dataverse and dataset, separate access roles can be attached to users or groups of users. These roles allow users a certain level of access privilege: reading, editing, publishing, etc.
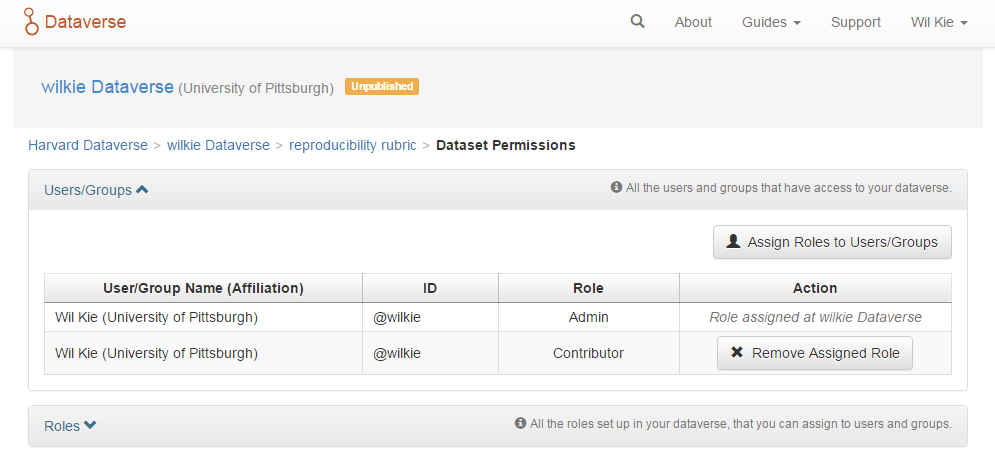
Provenance
Uploaded files have their MD5 hash specified which allows others to verify the integrity and easily compare with datasets elsewhere.
Datasets and files are given DOIs automatically. These serve as global identifiers and can be used as URIs to allow other resources to link to the library.
Governance
The source code is open source and available for modification. It has a permissive license which allows for modification and redistribution.
Harvard's dataverse has a comprehensive preservation policy. It reports that it maintains a "full backup of all data and directories." There is a backup of application and system files nightly which is stored off-site for 45 days. A secondary backup of all data files happens every 4 hours to a second off-site storage array in Boston. This is stored on a system that is designed to provide this backup "long-term."
Strengths
To be discussed.
Breakdown
Weaknesses
To be discussed.
Breakdown
Unique Features
To be discussed.
Best-Practice Influences
To be discussed.
Digital Library Incorporation Issues
To be discussed.